基本组成 1 2 3 4 5 6 7 8 9 worker_processes 1; # 工作核心 events { worker_connections 1024; # 最大连接数 } http { # 具体服务 }
代理 代理分为正向代理和反向代理
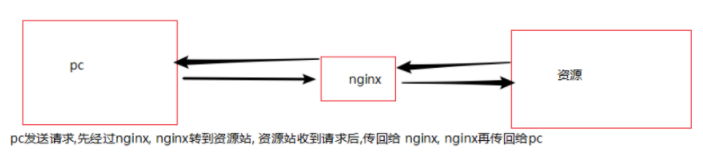
正向代理 如果把局域网外的Internet想象成一个巨大的资源库,则局域网中的客户端要访问Internet,则需要通过代理服务器来访问,这种代理服务就称为正向代理(也就是大家常说的,通过正向代理进行上网功能) .如下图所示
正向代理允许客户端通过它访问任意网站并且隐藏客户端自身,因此你必须采取安全措施以确保仅为经过授权的客户端提供服务. 对于用户而言,他是有感知的,明确知道需要访问中转站,这点与反向代理完全不一样
正向基本配置 1 2 3 4 5 6 7 8 9 10 server { listen 80; server_name localhost; location / { root html; proxy_pass http://127.0.0.1:8000; index index.html index.htm; } }
说明: 当我访问80端口时,呈现在我页面的是 8000端口提供的内容
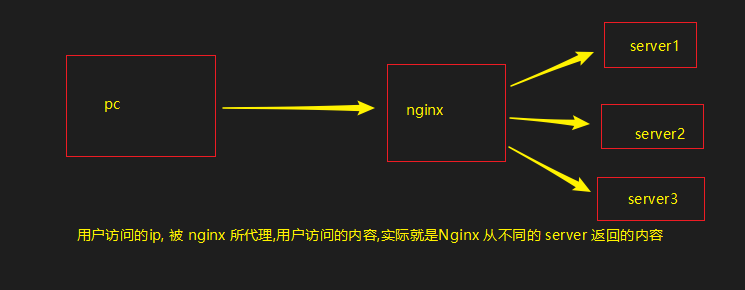
反向代理 反向代理,对于用户而言是无感知的(无需配置),用户访问的是一样的地址,但是资源来源可能来自上百个资源站
反向基本配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 # power by www.php.cn #user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #tcp_nodelay on; fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; fastcgi_buffer_size 128k; fastcgi_buffers 4 128k; fastcgi_busy_buffers_size 256k; fastcgi_temp_file_write_size 256k; #gzip on; gzip on; gzip_min_length 1k; gzip_buffers 4 32k; gzip_http_version 1.1; gzip_comp_level 2; gzip_types text/plain application/x-javascript text/css application/xml; gzip_vary on; gzip_disable "MSIE [1-6]."; server_names_hash_bucket_size 128; client_max_body_size 100m; client_header_buffer_size 256k; large_client_header_buffers 4 256k; server { listen 9001; server_name localhost; location / { root html; proxy_pass http://127.0.0.1; index index.html index.htm; } location ^~ /addUser/ { proxy_pass http://127.0.0.1:8000; } location ^~ /add2/ { proxy_pass http://127.0.0.1:3000; } } }
说明: 当我访问9001端口时, nginx 反向代理到 http://127.0.0.1 服务上. 当我访问 :9001/addUser 时, 实际返回的是8000端口的服务,访问 :9001/add2 时,实际返回的3000端口的服务. 但是对于9001端口而言,并不用做任何配置,我不用考虑到底是哪个服务给于我数据,访问9001端口就行了.这个就是反向代理
负载均衡 在看负载均衡话题之前,希望读者先理解反向代理的概念. 因为有了反向代理,client 不用考虑到底是哪个 server 提供的资源,所以当访问量激增的时候,我们只需要加机器,就能实现加性能.
基本概念: 负载均衡是指,将请求分发到 多台 应用服务器,以此来分散 压力的一种架构方式,他是以集群的方式存在,并且当 某个节点挂掉的时候,可以自动 不再将请求分配到此节点。
负载均衡的配置方式
轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,
其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前 积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
具体配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #tcp_nodelay on; fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; fastcgi_buffer_size 128k; fastcgi_buffers 4 128k; fastcgi_busy_buffers_size 256k; fastcgi_temp_file_write_size 256k; #gzip on; gzip on; gzip_min_length 1k; gzip_buffers 4 32k; gzip_http_version 1.1; gzip_comp_level 2; gzip_types text/plain application/x-javascript text/css application/xml; gzip_vary on; gzip_disable "MSIE [1-6]."; server_names_hash_bucket_size 128; client_max_body_size 100m; client_header_buffer_size 256k; large_client_header_buffers 4 256k; # 负载均衡,需要注意 server 跟 proxy_pass 的格式不太一样,没有前缀 # weight 默认为1, 值越大,分配的几率越高 upstream myserver { server 127.0.0.1:8000 weight=1; server 127.0.0.1:3000 weight=5; } server { listen 80; server_name 127.0.0.1; location / { proxy_pass http://myserver; root html; index index.html index.htm; } } }
说明: 当用户访问80端口时, 8000/3000端口同时对其进行服务,默认采用轮询的方式